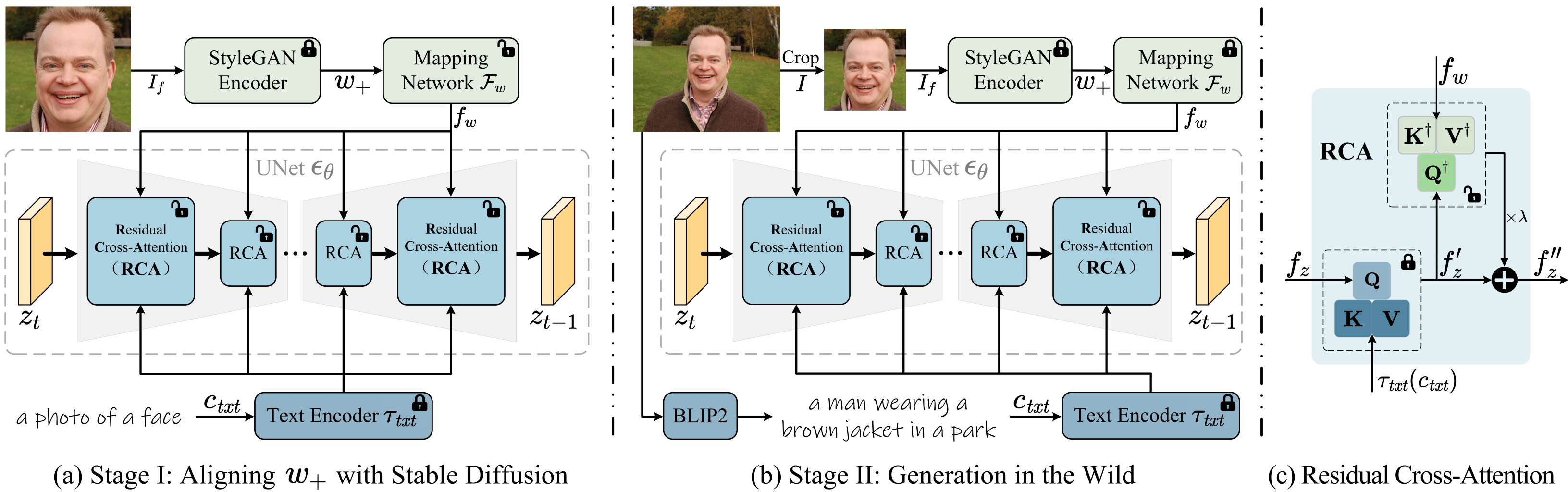
Text-to-image diffusion models have remarkably excelled in producing diverse, high-quality, and photo-realistic images. This advancement has spurred a growing interest in incorporating specific identities into generated content. Most current methods employ an inversion approach to embed a target visual concept into the text embedding space using a single reference image. However, the newly synthesized faces either closely resemble the reference image in terms of facial attributes, such as expression, or exhibit a reduced capacity for identity preservation. Text descriptions intended to guide the facial attributes of the synthesized face may fall short, owing to the intricate entanglement of identity information with identity-irrelevant facial attributes derived from the reference image. To address these issues, we present the novel use of the extended StyleGAN embedding space W+, to achieve enhanced identity preservation and disentanglement for diffusion models. By aligning this semantically meaningful human face latent space with text-to-image diffusion models, we succeed in maintaining high fidelity in identity preservation, coupled with the capacity for semantic editing. Additionally, we propose new training objectives to balance the influences of both prompt and identity conditions, ensuring that the identity-irrelevant background remains unaffected during facial attribute modifications. Extensive experiments reveal that our method adeptly generates personalized text-to-image outputs that are not only compatible with prompt descriptions but also amenable to common StyleGAN editing directions in diverse settings.